Core Architecture
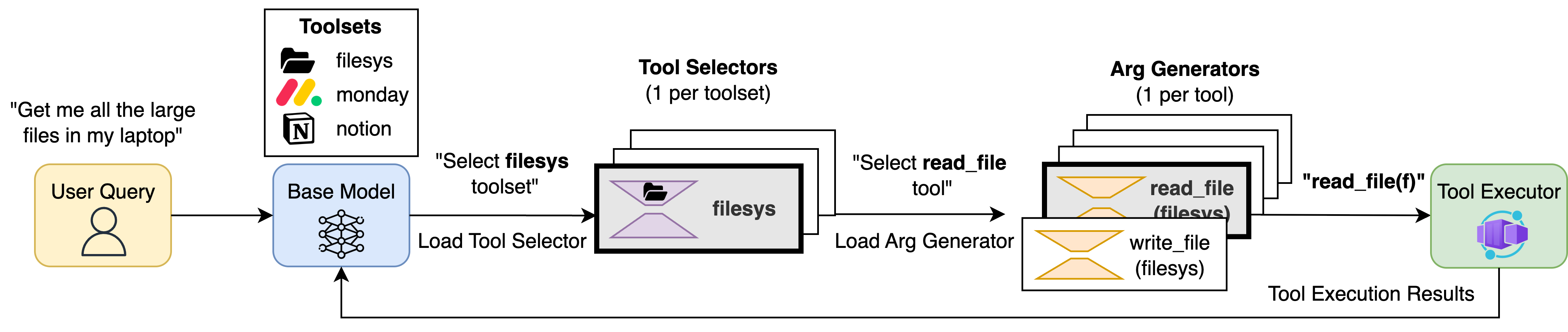
AgentFlux architecture showing the decoupled post-training pipeline and inference framework with specialized LoRA adapters
Agentic systems autonomously solve complex tasks through iterative cycles: decomposing goals into discrete steps, executing each by invoking external tools, and dynamically adjusting based on tool outputs. Success hinges on LLM orchestration—the system's ability to accurately select the right tool and generate correct arguments at each decision point.
AgentFlux fundamentally reimagines this orchestration. Rather than relying on a monolithic LLM orchestrator, it employs multiple specialized LoRA adapters trained through a decoupled post-training pipeline and coordinated by a novel inference framework.
Post-Training Pipeline
1. Tool Selector Adapter
Functions as a classifier, identifying the optimal tool for each workflow step during inference.
2. Argument Generator Adapter
Produces precise, context-appropriate arguments for the selected tool at each step.
Decoupled Inference Framework
Classification Sub-Step
Dynamically loads the tool selector adapter to determine which tool to invoke.
Argument Generation Sub-Step
Dynamically loads the corresponding argument generator adapter to construct the tool's input parameters.
Inference Pipeline Flow
Toolset Selection
Base model routes to relevant toolset (Filesystem, Notion, Monday.com)
Tool Selection (Classification)
Load Tool Selector LoRA adapter → Classify which specific tool to invoke
Argument Generation
Load Argument Generator LoRA adapter → Generate precise, structured arguments
Tool Execution
Execute in containerized sandbox → Return observation → Continue or summarize
Complete inference pipeline showing hierarchical orchestration with dynamic LoRA adapter loading